This is the third in a blog series on list building in the Wikimedia movement. In the last post, I covered approaches on-wiki communities use to create to-do lists within common behaviors on Wikimedia wikis. This post highlights the rapidly growing use of Wikidata to meet the same use case. If you want to learn more about the series, see the first post.
If you are not familiar yet: Wikidata is a sister project of Wikipedia. It stores key metadata about concepts in Wikimedia projects, like the data present in Infoboxes on Wikipedia articles. Wikidata has revolutionized how the Wikimedia ecosystem thinks about its data, creating a central place to share and translate those key data points, rather than updating infoboxes and other key pieces of information across the wikis.
Additionally, Wikidata uses a machine-oriented query service and API to allow users to ask complex questions of that data. By combining previously unplanned combinations of concepts, Wikidata takes us from hierarchical sets of knowledge (i.e. the sets created by manual lists or categories that I described in the last blog) towards a more organic, natural clustering of topics akin to how we actually associate topics together in thinking and learning.
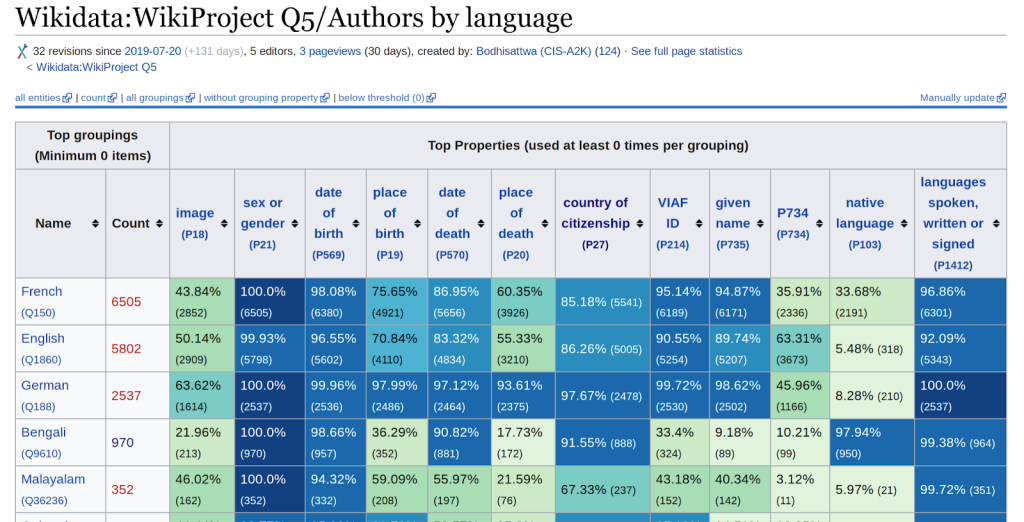
The value of Wikidata for lists is particularly visible as we plan to create a more equitably accessible and representative range of content on our platforms as part of Wikimedia 2030. With lists driven by Wikidata, it is much easier to understand where knowledge can be exchanged across our multilingual and multicultural communities. Additionally, Wikidata itself has a number of different workflows driven by list building. Recently, my colleagues at Wikimedia Deutschland completed a small research study that surfaced the importance of lists in existing complex workflows on Wikidata.
In this post, I am going to describe three principal methods for leveraging Wikidata to create lists. I am going to assume that you have a passing familiarity with how Wikidata works. If you haven’t been introduced to Wikidata, I recommend checking out this webinar, this self guided course or the documentation on Wikidata. My own experience in the movement is heavily reflected in this post, so many of the examples are from International or Anglophone uses of Wikidata.
Creating a dynamic list via Wikidata Queries
The basic method for asking a question of Wikidata is the Wikidata Query. The first step in creating a Wikidata list is figuring out the right question to ask of Wikidata and asking it. We do this with a tool called the Wikidata Query Service. If you have never written a Wikidata Query, I recommend checking out my previous medium post on Finding Women Writers from North Africa. Once you have a query, you can do a number of different things with it, which we will explore below.
If your goal is to create content on Wikimedia projects, you can extend an existing Wikidata to find missing topics on a Wikipedia (or other Wikimedia project) and create a red link list. The critical line of the query language SPARQL to add is:
FILTER NOT EXISTS { # has no en.wikipedia sitelink
?wiki schema:about ?item .
?wiki schema:isPartOf <https://en.wikipedia.org/> .
}
The code asks the Wikidata data model if a Wikipedia page from English Wikipedia is attached to the Wikidata items in the query. By modifying the url string after “schema:isPartOf” you can solicit topic lists from any other language Wikipedia (or other projects). If you choose to create local redlink lists on your wiki with Listeriabot for this query don’t forget to add the variable “?wiki” (or the equivalent in your query) to the output.
Not all topics on Wikidata are notable for Wikipedia — so some of the lists on Women in Red have added another feature as well to their queries: a count of all the links to other Wikimedia projects:
OPTIONAL {?item wikibase:sitelinks ?linkcount .} # count of sitelinks
By counting the number of links to other Wikimedia projects, we develop a rough proxy for “likely notable because it is covered in another Wiki”. It is important to be careful and not assume all topics in other wikis are automatically easy to write about or translate: different wikis have different notability and original research standards. However, for the most part, coverage elsewhere suggests that Wikimedians find that item worth including in a Wikipedia.
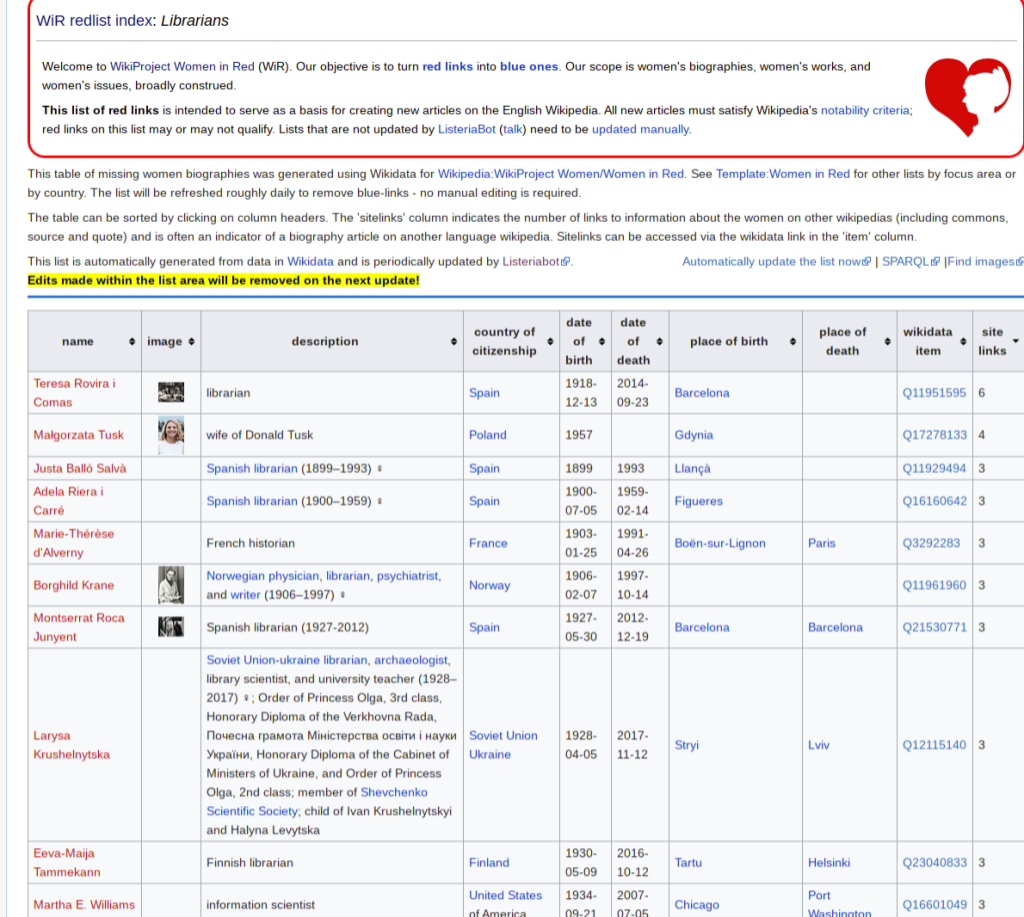
Wikidata Queries automatically update as the dataset on Wikidata changes — so once a query is written you will continue to find content on Wikidata that meets your criteria. Additionally, if something no longer fits within the query, it falls off the list. This makes Wikidata queries, dynamic and fluid and good for finding gaps in Wikipedia — this has a flip side: you can’t maintain a concrete list that you want to “finish” with most Wikidata queries (see solutions to this in the next couple of sections).
Once you have generated a Wikidata query, the Wikidata query can be fed into a number of other tools that can be used to solicit action from members of the community. If you are interested in translating Wikidata labels for example, the Tabernacle tool provides an interface for translating and manually adding data to a batch. Or ListeriaBot is how Women in Red and other projects, creating “red link lists” that are automatically maintained.
These queries can also be paired with on-wiki tools that help newcomers approach writing new articles. For example, on English Wikipedia, the Metropolitan Museum GLAM partnership adopted the template Preloaddraft to prepopulate articles on Wikipedia based on their information in Wikidata by integrating the template into query results. Originally created to support an Antartic Women Editathon to help new editors understand what should be included in a Wikipedia article, this generic template can help start articles in dozens of different domains. I saw this same tactic help newcomers write new articles during a recent editathon hosted by Wikimedia D.C. with an Asian American Literature Festival, they combined that new template with the results in the worklist to generate draft articles outlined for the newcomers (for example).
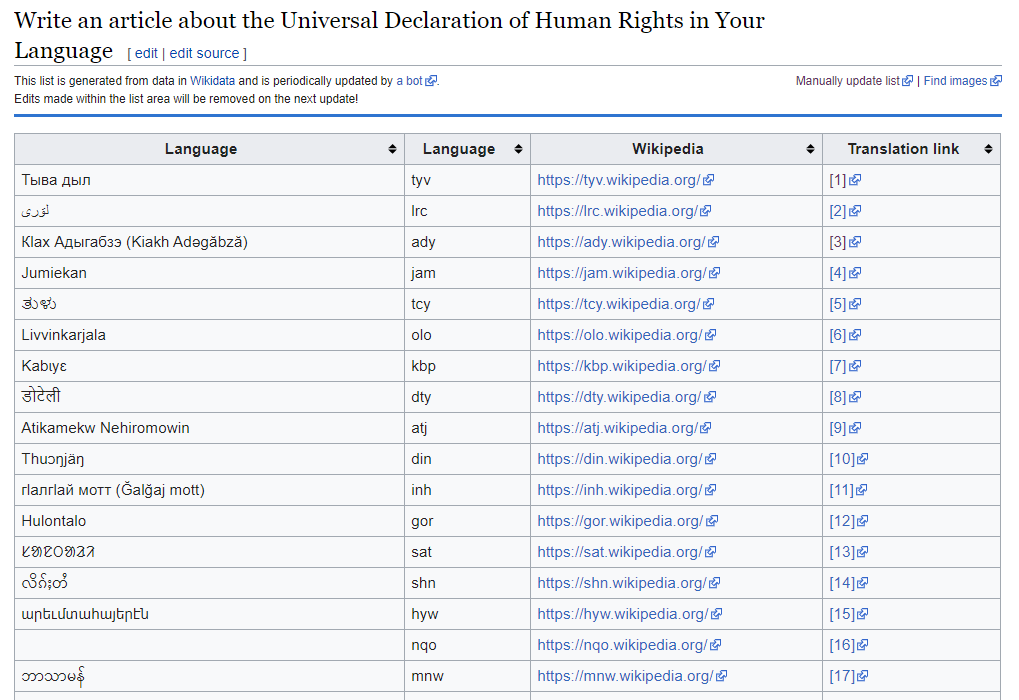
Or if you are running a translation initiative, you can connect the query directly with the Content Translation tools, by modifying the query to identify if a) the article exists in existing Wikis, and b) BIND the potential translation into a URL that translators can click on once to enter the translation workflow. We experimented with this for #WikiForHumanRights in January 2020 (see experiment page), and it allowed us to solicit, very quickly, with little manual work, translations of the article about the Universal Declaration for Human Rights.
Generating a list that mixes different data
Mixing data across Wikis can be a fairly complex task in the Wikimedia ecosystems. You frequently see these kind of data mixes through custom tools which extract data on a specific topic area (i.e. the Monumental for the Wiki Loves Monuments Data Set, Crotos for the Sum of All Paintings Data set, Scholia for bibliographic data, or the CEE Table Module used for CEESpring), for a specific action (for example, Citation Hunt which focuses on Citation Needed statements or WikiShootme a tool for capturing images of items with geocoordinates on Wikidata but now image) or complex batch processing done to facilitate batch editing such as for Bots or AutoWikiBrowser.
The most flexible generic tool for creating data intersections is the Petscan tool. Petscan allows you to scrape or retrieve data from all the gathering methods I have described so far in this blog series — lists of links on pages, templates, categories, and Wikidata queries — to create different intersections of that data with AND/OR/NOT functions. This allows you to produce lists that are both complex, and conceptually interesting, but also highly useful for various forms of maintenance and targeted contributions.
For example, I recently discovered the maintenance Petscan queries on the template Image Template Notice on Commons that is used on Wiki Loves Monuments categories. For my own personal workflows, these kinds of queries can be exceptionally useful. For example, when traveling in Ghana for the Movement Organizers Research, I realized that the local community was creating Wikipedia articles with categories but didn’t always create Wikidata items with properties: now I have an updatable worklist to prioritize Wikidata content to enrich.
Petscan can be the foundation of a number of different actions: for example, you can implement QuickStatements-type logic via the Petscan tool to add or remove statements on Wikidata. Or once these sets have been created, Magnus’s “Pagepile” tool can be used to output the data into a semi-permanent list format that can be used other tools offwiki, like Tabernacle or Wikihub, the worklist claiming tool built last year during Google Summer of Code.
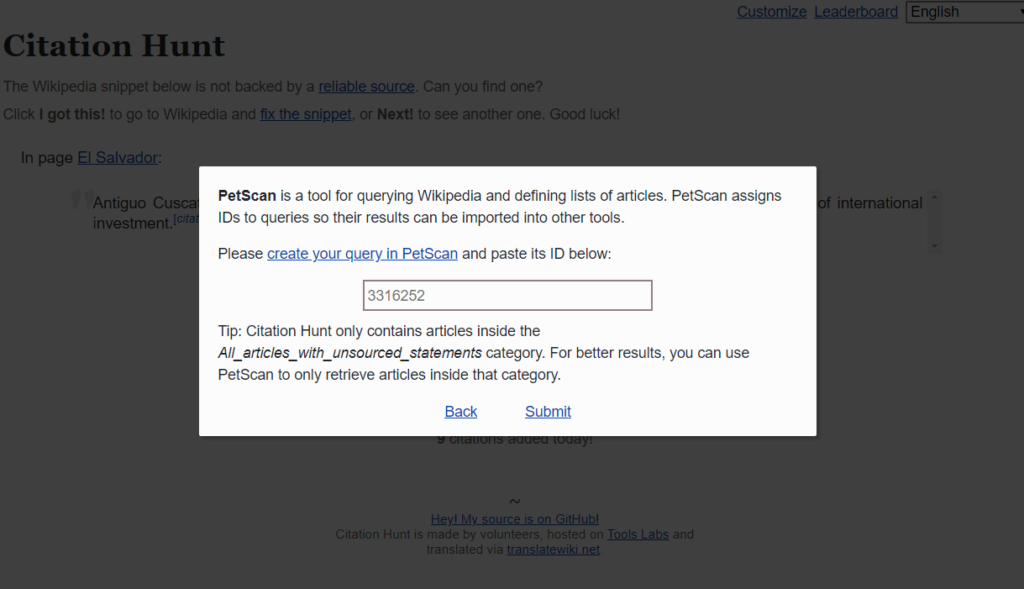
Lists from Petscan can be used to strengthen other tools and workflows. Based on feedback for #1lib1ref, we implemented a Petscan feature on CitationHunt that allows for custom queues of “citation needed” statements for editathons. Or the Programs and Events Dashboard allows you to put a “Petscan” id into Tracking for article constrained events, so that it automatically only tracks contributions to a subset of data. Other data formats, like CSV, on wiki tables, and others can be the foundation for other kinds of computation or tools which can apply the same list from Petscan against other applications. The new AC/DC tool on Commons can ingest a Pagepile and add Structured Data on Commons statements (kindof like Quickstatements on Wikidata).
As amazingly powerful as these mixed data lists are: I believe we are missing a lot of applications for these “mixed-data, machine generated lists” because it’s quite hard to use them without either the bespoke tools described in the first paragraph of this section or a tool using PagePiles off wiki. This means that the “average” Wikimedia organizer wanting to use, maintain or a list in their workspace needs to overcome several learning barriers. On Wiki lists are simply easier because you don’t have to understand the complex Wikimedia tooling ecosystem to replicate what feels like a core behavior. If you have ideas, I recently wrote a Phabricator ticket — please share your ideas or example uses.
If you are looking for fun, inspiring or simple ways to take advantage of these lists, or Wikidata in general, my colleague Sandra Fauconnier wrote a wonderful post in March 2018 about using the lists to edit for Women’s History Month.
Creating a custom list on Wikidata
One of the newer, and not fully explored techniques for “list building” is the use of a property P5008 (“on focus list of Wikimedia project”). This property was created in order to facilitate lists that are needed for community efforts but don’t have “obvious” ways of being coherent using a Wikidata query (i.e. existing properties don’t make it easy to query, but they belong together in some abstract way).
The first major use of the property was for Black Lunch Table’s list of artists. Ethnicity for communities of African descent both within and outside of the African diaspora is challenging — it’s both something that can be socially inscribed on people by society or can be something individuals determine on their own. Using a property like ethnicity on Wikidata was not appropriate for the Black Lunch Table organizers. Therefore they needed to curate a list that described the scope of their work (“black” artists) without prescriptively describing them with a claim like ethnicity. Thus the Wikidata community developed P5008, and Black Lunch table built their ongoing lists of artists within the scope of their project.
P5008 is applied to items to highlight them as “part of the list” that any number of different communities are working on. Thus far, there hasn’t been a deep use of qualifiers to modify these statements to create subsets within projects, but, for example Black Lunch Table creates geographic subsets with qualifiers for geographies that the individuals are focused on: for example on Zora J Murff. We could imagine many other kinds of potential lists where, for example, groups like the Wikidata Cultural Data Observatory, feeding missing topics or high impact topics for different communities through P5008 statements, and using qualifiers to determine a point in time (P585) of creating the recommendation, determination method (P459), main subject (P921) etc. We set up a WikiProject recently to discuss using P5008 and other properties to identify gaps like this.
Recently, I have been experimenting with the use of the property for identifying and representing the WikiProject Human Rights content so that we can better understand the opportunities for working with the UN Office of the High Commissioner on Human Rights. For example, with this property, I was able to leverage the existing set of items on WikiProject Human Rights in English Wikipedia, to identify those same items on Wikidata and with that you can begin to do various types of initial analysis (i.e. what types of articles are being covered in the WikiProject, what is the representation of different countries in the WikiProject’s people articles vs generally have an occupation “human rights activist” or some subclass of ). By leveraging Wikidata it is quite easy to see the relative depth of coverage for Human Rights topics favors Anglophone countries.
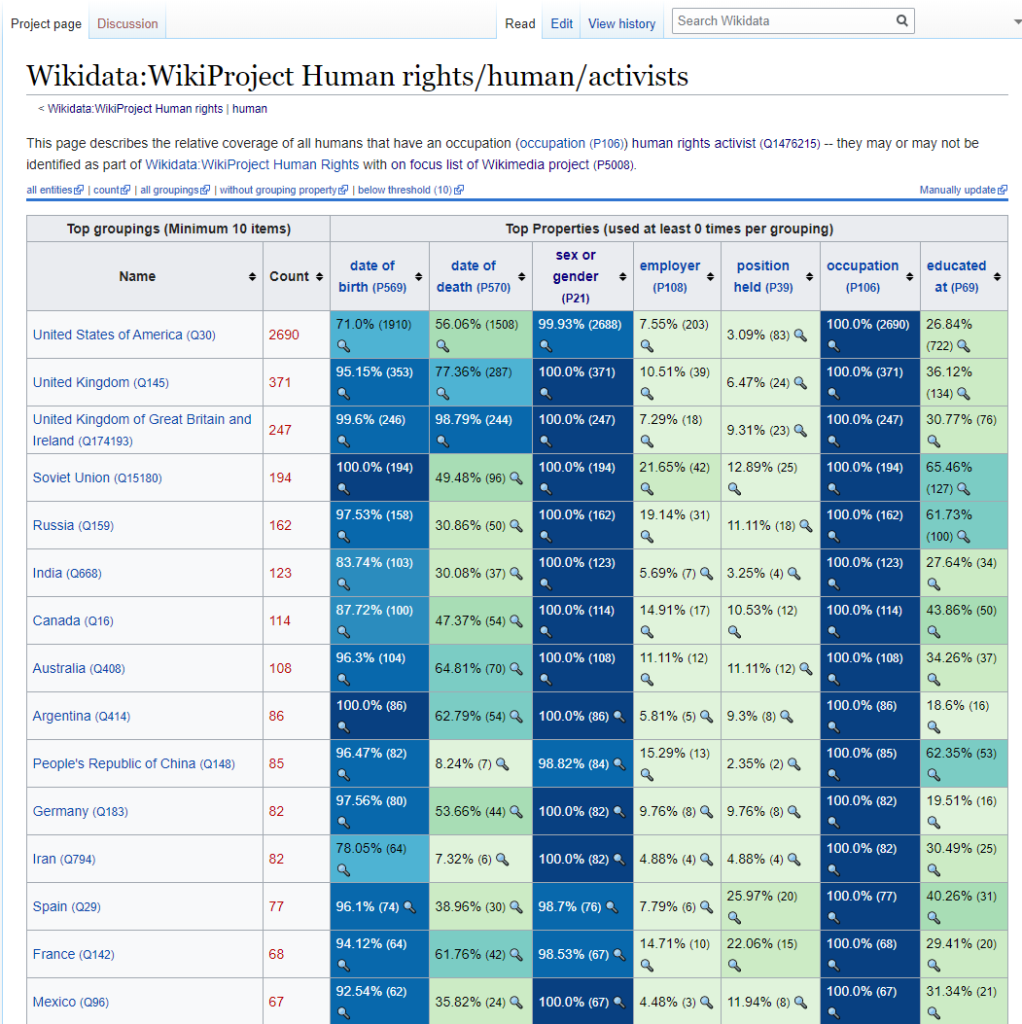
In a way P5008 “lists” combine the best features of Wikidata, the mixed data lists and the manual lists: as another Wikidata property it can be queried and produced with list making tools like Petscan and Listeria; identifying and “adding” items to the list is straightforward: find them and add the property P5008 either manually or in batch; and because the statement is tied directly to the project’s Q number, it is very unlikely to “lose” a P5008 statement unless the topic was added in error. P5008 offers a potential consistent and transparent future call to action.
What’s next?
Wikidata unlocks a lot of powerful and interesting ways to generate lists using the existing infrastructure within the community. Like many other applications of Wikidata for linked data, however, it’s still very emergent: the potential is imagined, initial applications of it are proving rather interesting, but there’s not a widespread ability to use those list making practices consistently with limited technological experience.
Yet at the same time Wikidata, is beginning to gesture towards a much more exciting future: generating lists with multiple forms of input, and serving in different ways. What if humans didn’t have to entirely “know” what belong on the list to find it? What if the Wikimedia ecosystem could “suggest” topics that belong to a list with little or no prior awareness about the topic from the editors?
With the increasing use of machine learning on the Wikimedia Projects, I expect the future of list-building will get an injection of AI aided topic suggestion! The fourth, and final, part of this series will examine that.
Like this blog series on lists? We need your help documenting list building practices and imagining new and more powerful ways to leverage the list building practices we have so far in the community: how would you make the lists more portable? What kinds of lists or data would you like to collect? If you do something I haven’t covered yet, let me know either by reaching out directly via astinson@wikimedia.org, leaving a comment on this post, or sharing the examples on the talk page of the Organizer Framework for Running Campaigns .
Can you help us translate this article?
In order for this article to reach as many people as possible we would like your help. Can you translate this article to get the message out?
Start translation